인덱스(index) 는 원하는 데이터에 더 빠른 접근을 할 수 있는 역할을 한다. 즉, 검색 성능을 향상시킨다. 예를들어, ID 가 주어진 student record 를 조회하기 위해, database systme 은 해당 record 가 있는 disk block 을 찾기 위해 인덱스를 조회한 다음, 적절한 student record 를 가져오기 위한 disk block 을 가져온다. 인덱스는 database 에서 효율적인 쿼리 처리에 필수적이다. 인덱스가 없다면, 모든 쿼리는 사용하는 모든 relation 의 모든 내용들을 읽어야 하므로 상당한 시간을 소모하게 된다.
인덱스에는 크게 두 가지 종류가 있다.
Ordered indices : 값들의 정렬된 순서를 기반으로 한다.
Hashing indices : 다양한 buckets 를 통한 값들의 균일한 분배를 기반으로 한다. 값들이 할당되는 buckets 은 hash function 으로 불리는 function 에 의해 결정된다.
file 에서 record 를 조회하기 위해 사용되는 attribute 혹은 attribute 의 set 을 search key 라고 한다. search key 개념을 사용하면, 여러 개의 인덱스가 있다면 search key 도 여러 개가 있음을 알 수 있다.
index file 은 index entries 라고 불리는 records 로 구성되어 있으며, 보통 original file 보다 훨씬 크기가 작다. index entry 의 형태는 다음과 같다.

index entry 또는 index record 는 search-key 값과 하나 이상의 records 를 향한 pointer 로 구성되어있다. record 를 향한 pointer 는 disk block 과 disk block 내의 offset 으로 구성되어 있다. offset 은 block 내의 record 를 확인하기 위해 사용된다.
Ordered Indices
ordered index 는 search keys 의 값들을 정렬된 순서로 저장하고 search key 를 포함하는 records 와 연결한다. file 에는 여러 index 가 있을 수 있다. 만약 records 를 포함한 file 이 순차적으로 정렬되어있다면, search key 또한 file 의 순차적인 순서를 정의하는 index 를 cluster index (primary index) 라고 한다. clustering index 의 search key 는 보통 primary key 이다. clustering index 가 있는 search key 에 의해 정렬된 file 을 index-sequential file 이라고 한다.
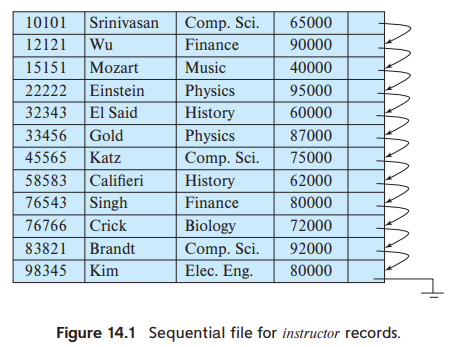
위의 그림은 instructor records 의 sequential file 이다. records 는 search key 로 사용된 instructor ID 에 의해 순차적으로 정렬되어 저장되었으므로 index-sequential file 이다.
search key 가 file 의 순차적인 순서와 다른 순서로 명시한 index 는 nonclustering index 또는 secondary index 라고 부른다.
ordered index 에는 두 가지 종류가 있다.
Dense index
index entry 가 file 내의 모든 search-key 값에 나타난다. index record 는 search-key 값과 search-key 값에 기록된 첫번째 data 를 향한 pointer 로 구성되어있다. 같은 search-key 값을 가지는 나머지 records 는, index 가 clustering 하나이고 records 는 같은 search key 로 정렬되어 있으므로, 첫 번째 record 이후에 순차적으로 저장된다.

위의 그림은 instructor file 에 대한 dense index 이다. ID "22222" 를 가진 instructor 의 record 를 찾으려면, 원하는 record 를 향하는 pointer 를 따라가면 된다. ID 가 primary key 이기 때문에 ID 가 "22222" 인 record 는 하나뿐이여서 검색이 종료된다.

위의 그림은 search-key 가 dept_name 인 instructor file 의 dense clustering index 이다. 즉, search-key 값이 primary key 가 아닌 상황이다. instructor file 은 depth_name 에의해 정렬되어 있으므로 depth_name 은 nonclustering index 가 된다. History departmet 의 records 를 찾기 위해서는, 첫 번째 History record 의 pointer 를 따라간 후, 원하는 record 를 만날 때 까지 poitner 를 따라가면 된다.
Sparse index
index entry 가 search-key 값들의 일부에만 나타난다. Sparce index 는 relation 이 search key 의 정렬된 순서로 저장되었을 때만, 즉 index 가 clustering index 일 경우만 사용 가능하다. record 를 찾으려면, 찾고 있는 search-key 값과 작거나 같은 search-key 값 중 가장 큰 값을 가지는 index entry 를 찾는다. 해당 index 가 가리키는 record 를 시작으로, 원하는 record 를 찾을 때 까지 file 의 pointer 를 따라간다.

위의 그림은 instructor file 에 대한 sparse index 이다. ID "22222" 를 가진 instructor 의 record 를 찾으려면, "22222" 의 index entry 를 찾으면 안된다. "22222" 이전의 마지막 entry 는 "10101" 이기 때문에 , "10101" 의 pointer 를 따라간 후 원하는 record 를 찾을 때 까지 순차적으로 정렬된 instructor file 을 읽으면 된다.
record 를 찾는데 sparse index 보다 dense index 를 사용하는 것이 보통 더 빠르다. 하지만 sparse index 는 dense index 보다 더 적은 공간을 요구하고 입력과 삭제에 대해 더 적은 maintenance overhead 를 요구하는 이점이 있다. 따라서 둘 사이에는 access time 과 space overhead 에 대한 tradeoff 가 있으므로, 상황에 맞추어 선택해야 한다.
Multilevel Index

index file 이 main memory 에 담을 정도로 충분히 작다면 entry 를 찾는 시간이 적게 걸린다. 하지만 index file memory 에 담을 수 없을 정도로 크다면 disk 에 저장해야고, disk read 에는 시간이 많이 소요되므로 entry 를 찾는 시간이 커진다.
이러한 문제를 해결하기 위해, disk 에 보관하는 index 를 sequential file 처럼 다루고 그 안에 sparse index 를 저장한다. basic index 의 sparse index 를 outer index 라고 하고, basic index file 을 inner index 라고 한다.
record 를 찾으려면 우리가 원하는 값보다 작거나 같은 search-key 값 중 가장 큰값의 record 를 먼저 찾아야 한다. 이를 위 outer index 에 binary search 를 사용한다. pointer 는 inner index 의 block 을 가리킨다. 우리가 원하는 값보다 작거나 같은 search-key 값 중 가장 큰 값을 찾을 때까지, inner index 의 block 을 스캔한다. 스캔이 끝나면, record 의 pointer 는 우리가 찾던 record 를 포함한 file 의 block 을 가리킨다.
records 를 multilevel index 를 사용해 찾는 것이 binary search 를 통해 records 를 찾는 것 보다 더 적은 I/O operations 를 요구한다.
index 의 형태와 상관없이, file 에서 record 가 update 되거나 delete 되면 모든 index 는 업데이트되어야 한다.
Nonclustering Index
nonclusering index 는 반드시 dense 여야 한다. clustering index 는 sequential access 에 의해 intermediate search-key values 를 찾는 것이 가능하기 때문에, search-key values 의 일부만 저장하는 sparse 여도 된다. 반면 nonclusering index 가 sparse 라면, intermediate search-key values 를 가진 records 는 file 어디든 있을 수 있기 때문에 전체 file 을 찾지 않고서는 찾을 수 없을 것이다. 이러한 현상은 cluster index 의 records 는 항상 정렬되어 있지만, nonclusering index 의 records 는 정렬되있지 않는 차이 때문에 발생한다.

만약 relation 이 같은 search key value 를 가진 record 가 하나 이상이라면, 해당 search key 는 nonunique search key 라고 불린다. nonunique search key 에 대한 secondary index 의 구현은 primary index 의 경우와 다르다. nonclusering index 의 pointers 는 record 를 직접적으로 가리키지 않고, 위 그림처럼 file 의 pointers 가 차례로 담긴 bucket 을 가리킨다.
Clustering Index and NonClustering Index

Clustering Index 와 Nonclustering index 를 함께 사용하는 경우, 위의 그림같이 인덱스가 구성된다. nonclustering index 의 pointer 는 해당 record 의 clustering index 값을 가지므로, nonclustering index 를 사용하면 clustering index 를 거쳐 데이터를 찾게 된다.
추가로 primary key 나 unique + not null 제약 조건을 설정하면 자동으로 clustering index 가 생성되고, unique 제약조건을 설정하면 자동으로 nonclustering index 가 생성된다.
Indices on Multiple Keys
위의 예시들에서는 search key 에 하나의 attribute 만 존재했지만, 보통 search key 는 하나 이상의 attribute 를 가질 수 있다. 하나 이상의 attribute 를 가지는 search key 는 composite search key 라고 한다. index 의 구조는 다른 index 들과 같으며 serach key 가 single attribute 가 아닌 list of attributes 라는 차이가 있다. search-key values 의 순서는 lexicographic ordering 이다. 예를 들어, two attribute search keys (a1, a2) < (b1, b2) 의 경우 a1 <= b1 이고 a2 < b2 를 만족한다. lexicographic ordering 은 alphabetic ordering of words 와 기본적으로 같다.
B+ Tree Index
index-sequential file organization 의 주된 단점은 file 이 커질수록 성능이 떨어진다는 것이다.
B+ tree index structure 는 data 의 insertion 과 deletion 에도 효율성을 유지하는, 가 널리 쓰이는 index structure 이다. B+ tree index 는 root 에서 leaf 까지의 모든 path 가 같은 길이를 가지는 balanced tree 이다. B+ tree 의 balanced 속성은 lookup, insertion, deletion 에서 좋은 성능을 보장해준다. 각각의 nonleaf node 는 floor[n/2] 와 n 사이의 children 을 가지며, n 은 특정 tree 마다 고정된 값이다. root 는 2 와 n 사이의 children 을 가진다.
B+ tree index 는 multilevel index 지만, multilevel index-sequential file 과는 다른 구조를 가진다. 우선 search key 가 unique 하다고 가정하자
Typical Node

위의 그림은 B+ tree 의 일반적인 node 이다. n - 1 개의 search key values (K1 ~ Kn-1) 와 n 개의 pointers (P1 ~ Pn) 로 구성되어 있다. node 안의 search-key 는 항상 정렬되어 있다. pointers 는 node 의 종류에 따라 children 을 가리키거나 records / buckets of records 를 가리킨다.
Leaf Node

leaf node 는 최소 floor[(n - 1)/2] 개에서 최대 n - 1 개의 (search-key) values 를 가질 수 있다. Li 와 Lj 가 leaf nodes 이고 i < j 라면 (Li 가 Lj 의 왼쪽에 있다면), Li 에 존재하는 모든 search-key value 는 Lj 에 존재하는 모든 search-key value 보다 작다.
만약 B+ tree 가 dense index 를 사용한다면, 모든 search-key value 는 항상 leaf node 에 존재한다.
pointer Pi (i = 1, ..., n - 1) 는 search-key value Ki 에 대한 file record 를 가리킨다. Pn 은 search-key order 의 다음 leaf node 를 가리킨다. 이러한 ordering 은 file 의 효율적인 sequential processing 을 가능하게 한다.
Nonleaf Node
nonleaf nodes 는 internal nodes 라고도 불린다. B+ tree 의 nonleaf nodes 는 leaf node 에 대해 multilevel (sparse) index 의 형태를 띈다.leaf nodes 와 구조는 같지만, nonleaf nodes 의 모든 pointers 는 tree nodes 를 가리킨다. 최소 floor[n/2] 개에서 최대 n 개의 pointers 를 가질 수 있다. node 의 pointers 갯수는 node 의 fanout 이라고 불린다.
node 가 m (m<=n) 개의 pointers 를 가진다고 생각하자. pointer Pi (i = 2, ..., m - 1) 는 Ki 보다 작고 Ki-1 보다 크거나 같은 search-key values 를 포함한 subtree 를 가리킨다. pointer P1 은 K1 보다 작은 search-key values 를 가진 subtree 를 가리킨다. Pn 이 가리키는 subtree 의 모든 search-keys 는 Kn-1 보다 크거나 같다.
다른 nonleaf nodes 와 달리, root node 는 floor[n/2] 미만의 pointers 를 가질 수 있다. 또한, tree 가 하나의 node 로만 구성되어 있더라도 최소 2 개의 pointers 는 가져야 한다.

위 그림은 n=4 인 B+ tree 의 예시이다.
Queries
B+ tree structures 와 binary tree 와 같은 in-memory structures 의 가장 큰 차이점은 node 의 size 와 그에 의한 tree 의 height 이다. B+ tree 의 경우, file 에 N 개의 search-key values 가 있다고 하면 tree 의 height 는 [log[n/2](N)] 보다 길지 않다. balanced binary tree 의 경우, tree 의 height 는 [log2(N)] 이 된다. N = 1,000,000 일때, n = 100 인 B+ tree 는 lookup 을 위해 4 nodes 가 필요한 반면 balanced binary tree 는 약 20 nodes 가 필요하다.
Updatees
record 가 relation 에 추가되거나 삭제되면, relation 의 indices 또한 변경되어야 한다. updates 에는 상당한 cost 가 소요된다.
==== B+ tree 의 insertion 과 deletion 은 내용이 커 나중에 정리하겠다 ====
Hash Indices
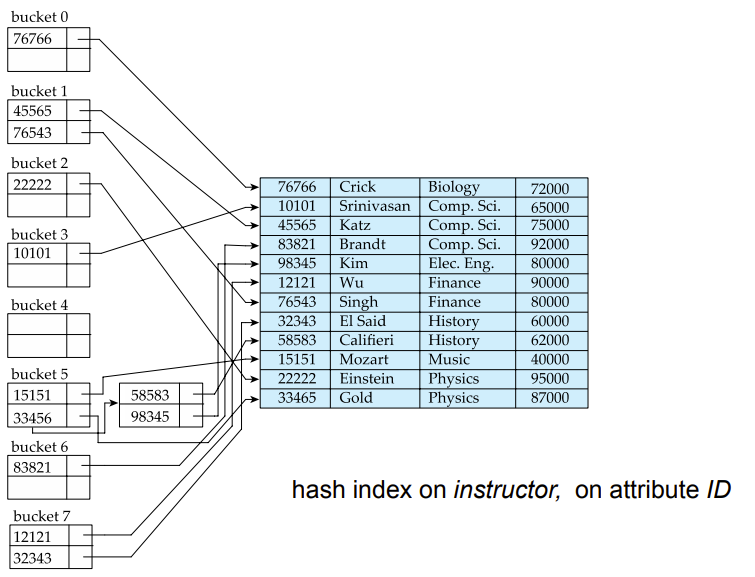
hasing 에서 사용되는 bucket 은 하나 이상의 records 를 저장할 수 있는 storage 의 단위이다. in-memory hash indices 라면 bucket 은 entries / records 의 linked liist 일 것 이고, disk-based hash indices 라면 bucket 은 disk block 의 linked list 일 것이다. K 를 set of all search-key values 로 B 를 set of all bucket address 로 가정하면, hash function h 는 K 에서 B 로 가는 function 이다.
예를 들어, search key K5 와 K7 이 같은 hash value 를 가진다고 하자. 찾는 record 의 search-key value 가 K5 라면 먼저 bucket h(K5) 를 확인해야 한다. bucket h(K5) 는 search-key value 가 K5 인 records 와 K7 인 records 를 모두 가지고 있으므로, 원하는 recored 를 찾기 위해서는 bucket 내의 모든 record 의 search-key value 를 확인해야 한다. search key 의 deletion도 같은 방법으로 수행된다.
B+ tree indices 와 달리, hash indices 는 range queries 를 지원하지 않는다.

disked-bash hash index 에서는, record 를 삽입할 때 search key 의 hasing 을 사용하여 bucket 에 위치시킨다. record 를 저장할 bucket 의 공간이 충분하지 않다면, bucket overflow 가 발생한다. 이러한 overflow 는 overflow bucket 을 사용하여 해결한다. 예를 들어 bucket b 에 bucket overflow 가 발생하면 system 은 b 를 위한 overflow bucket 을 제공하고 record 를 overflow bucket 에 삽입한다. overflow bucket 이 다시 가득 차면, system 은 다른 overflow bucket 을 제공한다. 주어진 bucket 의 모든 overflow bucket 은 linked list 형태로 연결된다.
bucket overflow 는 주어진 records 의 갯수에 비해 buckets 가 충분하지 않은 상황이나 일부 buckets 에 다른 곳 보다 많은 records 가 몰리는 현상, records 분배의 skew 에 의해 발생한다. skew 는 여러 개의 records 가 같은 search-key value 를 가지거나 선택된 hash function 이 key values 의 불균형 분배를 만들 때 발생한다. bucket oveflow 의 가능서을 줄일 수는 있지만 없애는 것을 불가하므로, 앞서 말한 overflow buckets 를 사용하여 bucket overflow 에 대처한다.
이제까지 설명한 index 를 생성할 때 buckets 의 수가 고정된 hash indexing 은 static hashing 이라고 불린다. static hashing 은 다음과 같은 문제점이 있다.
- 초기 buckets 수가 너무 작으면, file 이 커지면서 너무 많은 overflow 로 인해 성능이 저하된다
- 성장을 예상해서 공간을 할당하면, 상당한 양의 공간이 초기에 낭비된다.
- db 가 축소되면, 공간이 다시 낭비된다.
이러한 문제를 다루기 위해, buckets 수의 증가에 따라 hash index 를 재설정한다. 하지만 index 의 재설정은 시간이 오래걸려 비싼 작업이고, 일반 operations 를 방해한다. 더 나은 해결책으로 buckets 의 수를 동적으로 수정하는 dynamic hashing 이라는 방법이 있다.
Ordered Indices VS Hashing Indices
Hashing 은 보통 key 의 특정 값을 알고 있을 때 records 를 가져오는데 적합하다. O(1) 의 시간복잡도를 가지기 때문이다.
range queries 가 자주 쓰이면, ordered indices 가 더 나은 선택이다. Hashing 은 정렬되있지 않으므로 특정 범위에 대한 값들을 찾을 수 없기 때문이다.
실제로, 대다수의 DBMS 는 B+ tree index 를 사용한다.
참조
Database-System-Concepts-7th-Edition
https://youtu.be/edpYzFgHbqs
'COMPUTER SCIENCE > DB' 카테고리의 다른 글
| DB Lock 과 Isolation Level (1) | 2025.11.30 |
|---|---|
| [DB] Join (0) | 2023.02.14 |
| [DB] Transaction (0) | 2023.02.12 |


댓글